
Paper Break: HyperDreambooth
You can now train your face on a model 25x faster

Paper Break is a series where I look at an exciting, recent AI white paper from some of the biggest brains out there and try to make sense of it in a way that I can understand it

HyperDreambooth
tldr; You’ll soon be able to train a diffusion model like Stable Diffusion on a subject with just one source image at 25x the speed of current techniques, significantly less compute, and with a substantially smaller output file
Paper Name: HyperDreamBooth: HyperNetworks for Fast
Personalization of Text-to-Image Models
From: Google Research, Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Wei Wei Tingbo Hou, Yael Pritch, Neal Wadhwa, Michael Rubinstein, Kfir Aberman
When: Jul 13, 2023

Primer
Before we dive into this white paper, It’s essential to understand how training or tuning a diffusion model on a subject or style works now. If you’re familiar with this already, skip ahead to the breakdown.
If you want to use stable diffusion to generate portraits of a person, dog, or art in a specific style, then your best bet is to do some training. You can use img-to-img generation as you would in Midjourney, but you’re extremely limited in how much control you have over the output. Also, getting consistent generations across prompts would require reusing the same seed and even supplying another image. Ideally, you want the model to “remember” a face and be able to use it with a specific keyword in a prompt. Something like this:
A close-up portrait of ohwx woman sitting in a chair drinking coffee.
In this prompt, ohwx is the trigger word to inform stable diffusion to use the subject you trained. Depending on the method of training, this will look different. When it comes to training methods, there are four main ones right now:
All four methods work similarly1, but I will explain how they work. Again, if you want to get to HyperDreambooth, skip ahead.
Dreambooth
Dreambooth is the most straightforward of these four and serves as a foundation for the others.
Dreambooth takes two inputs:
The concept you want to train. This is probably a few sample pictures. In the above diagram, our concept is a woman.
The phrase with a unique identifier acts like a trigger word associated with your concept. Our identifier in this example is “ohwx“. Word with no meaning and is probably unknown to a model.
The whole point of Dreambooth is associating that unique identifier with the chosen concept. That’s it. So, how is it done? First, your phrase is converted to an embedding. I won’t go too deep here on embeddings because I don’t want to embarrass myself, but it’s a list of vectors. A vector is a list of numbers. So for each word in your phrase, it gets converted to a list of floating point numbers. So the word ohwx might look like this:
[0.23,0.46,0.13,0.76,0.04,........]Once the embedding for your phrase is created, two images are created from your sample—one with n amount of noise and one with (n-1) amount of noise applied to it. Let’s say n is 5. The five-noised image and the embedding are then passed to the model with the expected output to be a four-noised image. Afterward, a diff is performed against the original four-noised image created at the beginning and the new one.
From the diff, a loss check is performed. High loss means these images look nothing alike; a low loss means they are similar. Next, something called a Gradient Update is applied to the model. This means the model is either rewarded if the loss is low or punished if they are high. The model then adjusts its weights accordingly. The output is an entirely new model. GB’s in size.
This process runs in cycles up to the configured parameters. Depending on how much VRAM you have for your GPU and what settings you’re using, this could take over 30 mins. Even then, the results might not be high quality. You have to play around with it. I’ve spent hundreds of hours using Dreambooth to train faces to get that one good model. At this time, Dreambooth creates the best results when done right.
Textual Inversion
Textual Inversion is almost the same as Dreambooth, with some pretty cool changes that don’t seem like it should work.
With Textual Inversion, the Gradient Update is applied to the vector or the unique identifier instead of the weights on the model. Everything else is the same. To me, this seems like magic that just adjusting this vector over and over would eventually lead to some outputs with low loss.
The output of this training method is a tiny KB file because it’s just the vector. This makes it so easy to share with others and use different models.
LoRA
Low-Rank Adaptation, or LoRa for short, is similar to Dreambooth but has some important differences.
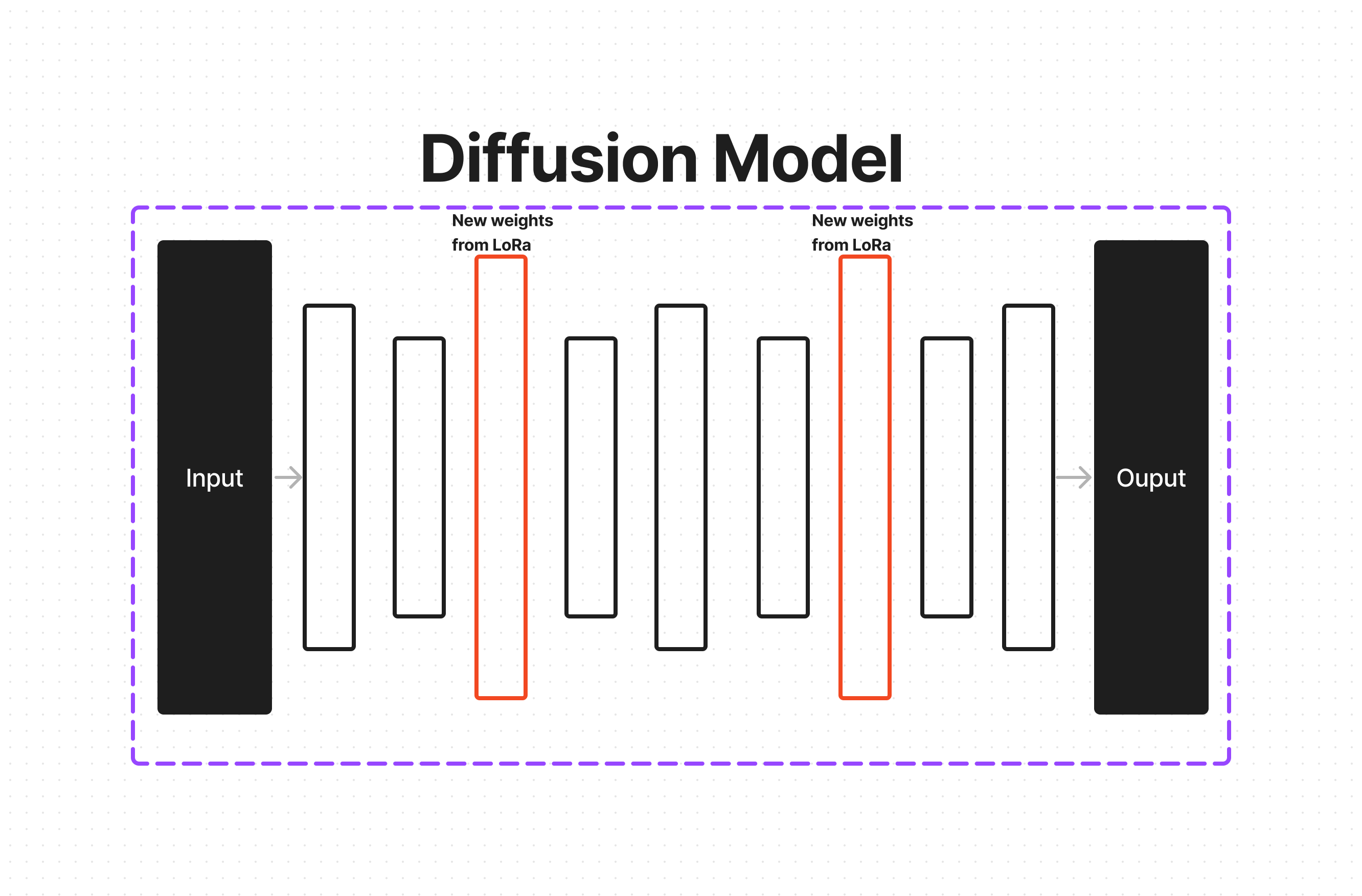
Dreambooth has a problem in that it makes a copy of the model. Stable Diffusion is not a huge model, so the copies aren’t too bad, usually around 2-3 GBs. Still big enough to affect storage, costs, and speed. Cold booting a GB+ file from Disk to VRAM will incur a speed penalty.
LoRa aims to solve this problem by inserting new weights into the model instead of making an entirely new one. Everything is exactly the same. When a Gradient Update is performed, the new weights in the inner layers of the Neural Network are adjusted. These weights are set up not to affect the model at all. When LoRA training starts, the weights pass through to the next.
When the loss is calculated, and gradient update is applied, the new weights are adjusted, changing their output and the inputs of the intermediate layers after them. This happens enough that eventually, the model can output that (n-1) noised image and have a negligible loss.
LoRA training is much faster than Dreambooth and takes much less memory. The layers are so much smaller, allowing you to pass them around and use them in any compatible model. They’re usually around 150MB. The quality is not as good as proper Dreambooth training, but it’s more than good enough. Because of these upsides, LoRA is currently the preferred method in the community, overtaking Dreambooth.
HyperNetworks
HyperNetworks is similar to LoRa, which is similar to Dreambooth.
The main difference is with the Gradient Update. With HyperNetworks, the update is applied to a network that creates the weights added to the model, like in LoRA. This network learns and adapts over time.
HyperNetworks are the less studied training methods in the context of Dreambooth. I couldn’t find an official paper on it. Lmk if you have! I’ve never used HyperNetworks because it just seemed like a sh*ttier LoRA 🤷🏾♂️.
HyperDreambooth
tl;dr
This excerpt talks about a way to use an additional smaller network (HyperNetwork) to adapt or 'tune' the weights of a primary network based on the data it sees. This is particularly effective in tasks that require a high level of customization, like personalizing a face image generation model.
Maybe that primer is overkill, but I find all this fascinating. My Engineering background is purely practical with a sprinkle of theory, so learning about cool CS stuff like this is candy for me.
HyperDream booth introduces new concepts with training but also takes advantage of previous techniques. As you might have guessed from the name, HyperDreambooth essentially uses HyperNetworks with Dreambooth. That is a disgustingly high-level view, so let’s break it down. There are two phases.
Phase 1: HyperNetwork

First is the training of a HyperNetwork that will output some weights. These weights have a strong initial direction, meaning the next phase won’t start from scratch and will only have to do some fine-tuning. The HyperNetwork comprises a Visual Transformer Encoder (ViT) and a Transformer Decoder.
The ViT translates face images into latent (hidden) features. These are abstract characteristics that help define and differentiate each face image. These face features are then concatenated (joined together) with a set of latent layer weight features. These are initially set to zeros and represent the learnable parameters of the primary network that the HyperNetwork will eventually generate.
The combined features are then passed into the Transformer Decoder, which iteratively refines the initial weights by making delta (change) predictions. This involves predicting how the initial weights must change to improve the primary network's performance. The final adjustments, or 'deltas'’ to the primary network's weights, are calculated by passing the decoder's outputs through a set of learnable linear layers. These simple neural network layers can adapt their parameters to improve performance.
The researchers highlight that the Transformer Decoder is an excellent fit for this task. This is because it can model the dependencies between the weights of different layers in the primary network (the diffusion UNet or Text Encoder mentioned). This is crucial when personalizing the model since changing the weights in one layer could affect how other layers should be adjusted.
They mention that previous works did not sufficiently model this dependency, but using a transformer decoder with positional embedding, they can effectively do so. This is similar to how a language model transformer treats words, where a word's position can influence its meaning in a sentence.
Phase 2: Lightweight DreamBooth (LiDB)

There is a bunch of cool math going on here that is beyond my smooth lizard brain, but I did my best to understand it. LiDB aims to reduce the model's complexity and size while maintaining the generated output's quality. It does so using a type of LoRA method called Rank-1 LoRA.
Rank-1 LoRA, from what I can tell, is when the model has a certain 'weight' or importance assigned to its different parts or features. These weights are organized in a matrix, and the "rank" of a matrix is a measure of how many of these features are linearly independent or not redundant. A "Rank-1" matrix has only one linearly independent feature.
Here is where the math comes in; bear with me :). The weight space in which the LiDB takes place is generated by something called a Random orthogonal incomplete basis, 🤷🏾♂️. I learned this after researching and talking with people who do math for fun. An 'orthogonal basis' is a set of vectors at right angles to each other; in this context, they form a basis for the weight-space. 'Random' means these vectors are chosen randomly, and 'incomplete' means the basis does not span the entire space but only a portion. This helps in making the model lightweight and more efficient.
The paper details how different matrices are selected, techniques like freezing layers, and what different layers do. These seem cool but are just beyond me.
Results

In the above image of results, you can clearly see how the HyperNetwork alone does not create great outputs. Combined with LiDB (fine tuning), however, the results are amazing.

Eventually, the output of LiDB is a tiny 120kb file! This file is magnitudes smaller than DreamBooth but offers very similar quality.
Sign out.
I can’t wait to see an implementation of HyperDreambooth out in the wild so I can give it a go. I haven’t seen anything yet, but I’m sure someone is working on it.